GraphQL Sessions: Powering Farfetch.com

By Manuel Garcia
In this article, we will describe how we adopted GraphQL at Farfetch.com and why we are using it to skyrocket our ability to build rich and amazing experiences for our users.
In order to better understand why we knocked on GraphQL’s door, let’s take a step back and review some of our architecture evolutions over the years. You might relate to some of the challenges of a microservice architecture. We will share our insights into how GraphQL can fit in such an architecture, and we hope it helps you in your own projects.
Evolution 1: The Slicing Architecture
Back in 2015, Farfetch.com was a big monolith struggling with its size and time-to-market. As with many other companies out there, it then moved bit-by-bit, or in this case slice-by-slice, towards a microservice architecture. This gave more autonomy to teams, sped up CI/CD, met high business demand, and helped FARFETCH grow its marketplace. We called each of these microservices slices, as we were slicing our Asp.net monolith.
The following diagram provides a high-level overview of our slicing architecture.

Each slice was responsible for a given section of a page. For instance, the header slice was responsible for rendering the header section and all its interactions. This slice was also the most exposed: it renders above-the-fold content on all pages and therefore experiences the highest throughput. The product details slice was responsible for the main section of our Product Details page.
In this sense, we bound slices to our visual organisation and, as a result, each slice only fulfils its own needs and does not depend on other slices. In addition, there is a central piece/brain here: our Portal. Among other things, it was responsible for understanding the incoming request, figuring out which slices were part of the request, fetching data from the necessary slices, and assembling the final response.
In this flow, we are mainly talking about SSR (Server Side Rendering), although we rendered some slices client-side. The responsible slice would process Ajax requests made in a specific section of the page, going through the Portal. The Portal acted as a gateway, forwarding the request to the appropriate slice.
In this slicing architecture phase, we distributed the rendering. Hence our Portal fetched HTML from the slices. We established a protocol for exchanging the HTML and all necessary assets to serve the user’s browser. Each slice served two main purposes: to fetch data and to call a JavaScript engine that would receive the fetched data and produce an HTML string.
Our front-end stack evolved and progressively moved from Asp.net Razor views to React. This also enabled front-end engineers to focus on their strengths without the mix of back-end tools/technologies/know-how.
This architecture grew over four years and, as with any sort of architecture, it was just a matter of time until our next evolution jump.
Evolution 2: Centralised Render
Our next stage demanded a shift from a distributed rendering approach to a centralised one. This might sound like a return to our monolith. Although we re-centralised our rendering, we kept our distributed data fetching.
Moving our front-end code to a mono repository was a big breakthrough, helping to make everything more consistent and easier to test. It also made it possible to have a single React isomorphic application. We were able to reuse the same code and specialise our desktop and mobile web channels. Each channel would have its node.js runtime capable of scaling independently, when necessary. We call these applications render apps. Below, we can see the architecture diagram with all the changes (render apps in green).
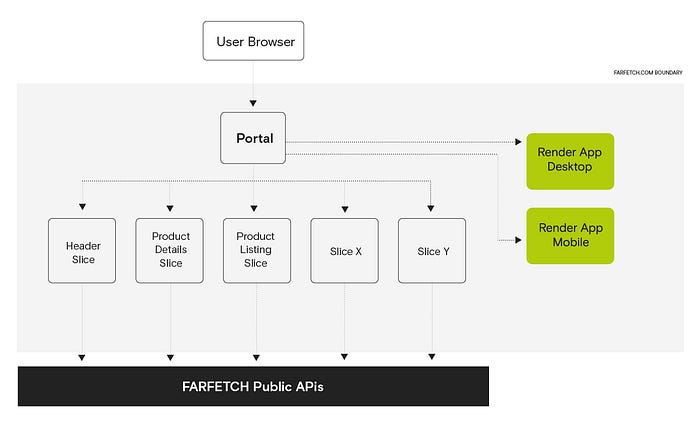
The SSR would work similar to how it was before but with a few important differences:
- The slices don’t render anymore. Instead, they exchange a JSON payload with the content that would be required to render the local HTML. The Portal receives several JSON payloads instead of HTML.
- The Portal joins all JSON payloads from slices. Instead of returning the response right away, it sends the assembled JSON to these new render apps (mobile or desktop, depending on the user’s browser) that have access to all our front-end code (React based). The Portal calls these render apps, specifying which layout should be used to render. Each page has its own layout. The Portal knows which page type is being requested and which render app layout should be used. Layouts can be created for a variety of use cases, assembling our React components together as the building blocks.
- When the render apps receive this big JSON payload, they execute all the JavaScript required for the designated page layout using the content available in the JSON. This JSON is segmented on a slice basis, which the front end is able to recognize. The render app generates the HTML and sends it back to the Portal.
- Rendering is centralised, allowing us to scale the rendering work independently from all the data fetching done by the slices.
In early 2021, we adopted this centralised render approach. But we didn’t wait long to push it even further.
These major evolutions of our front-end architecture built up more elasticity and consistency. However, it was still highly coupled with the back-end because of our slicing architecture design: it was very UI-oriented and tied to the JSON payload-fetching described above.
We called the data in these JSON contracts “initial states”, as they contain properties representing the whole universe of data required for the initial rendering of a certain part of the layout via our React components. If we needed to specialise a certain use case-such as a specialised product listing page for a specific user segment, market or channel-we could request this bloated bag of properties. Alternatively, we could implement a specific, trimmed-down initial states endpoint to prevent such a waste of data, computation, and resources. Specific scenarios require different sets of data that only the front-end knows about. This is precisely where GraphQL comes in.
Evolution 3: GraphQL — Why?
We decided to give more power and freedom to our front-end stack to build rich, specialised experiences for our very demanding marketplace users. It turns out that there could be different solutions to accomplish this.
Over the years we witnessed many companies bump into similar challenges. Typically their consumer apps create a layer in between their main APIs to aggregate and reshape the data into a more digestible representation. GraphQL enabled us to express the data the client wants via a graph. Through this graph, we are able to transverse the relationships between our entities.
When we are building experiences, we don’t really think about resources as in a REST API. Instead, we think more about entities with some properties and their relationships. This is not to say that REST APIs are bad and that GraphQL is better. It’s just that GraphQL is very appealing for this sort of use case due to its expressiveness.
We then created a long term vision for our Farfetch.com architecture to push the next evolution phases and where GraphQL could play a central role.
The Six High-level Requirements
This architecture supports six high-level requirements that help guide it in the right direction. They can be seen as a framework to measure the effectiveness of our architecture and to validate that we are making progress over time. The requirements are also aligned with our business needs to accelerate the FARFETCH marketplace. In a nutshell, these are the most important requirements:
Decouple Front-end from Back-end — The front-end and back-end represent different tiers in production and different codebases in development. Each side can be scaled separately without affecting the other. The front-end is able to evolve without constantly requiring feature parity on the back-end.
Front-end Maximum Flexibility — The front-end is a big puzzle with pieces of different granularity. We can easily reuse these pieces to create new experiences or different variations that are optimised for target devices (desktop, mobile, embedded systems, etc.) and tailored for specific audiences (user segments, countries, etc.).
Better Performance — Our architecture needs to create opportunities to improve overall performance. It’s hard to reason with an architecture that represents a slower experience for our users, which is misaligned with our performance culture.
Data Flow Inversion — The front-end tier directs the data flow and instructs the back-end tier on the ideal data to process a specific request, such as rendering. Other operations would follow the same flow.
Single Data Facade — Back-end complexity is hidden from the front-end tier via a single facade layer that offers data shaping and aggregation. Data should be open, easy to consume, general for cross-cutting concerns (e.g., translations) and specific for context-based scenarios (e.g., A/B tests). When applicable, data aggregation is delegated to different specialised back-ends (downstream services, former slices).
Back-end by Subject/Domain — The same back-end can attend data/operation needs coming from different parts of the site. This creates the need to organise back-ends by business subject or a set of features that can attend to general needs. It also avoids code duplication, enabling us to follow DRY (Don’t Repeat Yourself) principals.
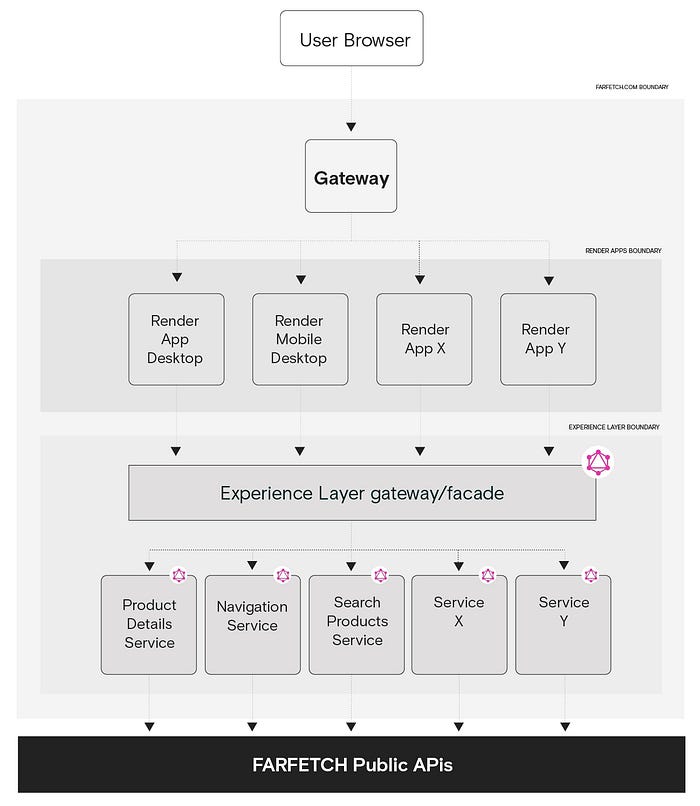
There is a lot to absorb with these requirements. But what probably matters most in this context are “Data Flow Inversion”, “Single Data Facade” and “Back-End by Subject/Domain”. All three lead to the creation of a new layer that we call the “Experience Layer” that would be 100% GraphQL.
The “Data Flow Inversion” creates the main shift. The front-end stack no longer waits for a massive initial state JSON payload to be dropped. The render app is now able to request what it needs in order to render the current page. With the right set of GraphQL queries/mutations, it can get exactly what it needs without all the bloat and waste.
“Single Data Facade” helps with making the whole Experience Layer easier to consume, abstracting all of the complexity behind it. We are introducing a GraphQL gateway with a single schema and a single point contact for the render app to communicate with. We have also abstracted this distributed schema from the consumer’s perspective (more details about the schema and its distributed nature in future articles). This enables us to concentrate on building a great schema. It also frees us up to make changes behind the gateway without affecting consumers, as long as we respect the schema contract.
“Back End by Subject/Domain” deprecates our slice architecture. We still want to preserve the advantages of a microservice architecture, but we also want to decouple the front-end from the back-end (our first requirement). For that to happen, we need to break up with the slicing concept that, by design, bound us to a visual separation of responsibilities. How would that happen in practice? We wouldn’t be throwing slices away but repurposing them to align with this architecture vision. We aim to progressively onboard more back-ends on the Experience Layer (behind the GraphQL gateway), further expanding our schema.
Although we didn’t prioritise a hard requirement to reduce complexity and costs, this architecture jump could help significantly. There’s a high number of slices with varying instances running in production. Some of these back-ends do the same sort of work.
For instance, the product details slice issues a call to the /products/{id} endpoint on our public API to fetch data about a specific product. Our bag and wishlist slices also do the same for their use case, as they fetch bag/wishlist data together with details about the products that are part of these lists. This implies some redundancy between different teams. It also expands our touchpoints with the public APIs, requiring teams to implement the same sort of resilience policies multiple times and requiring larger configuration updates when something changes.
The following is an example of the Shopping Bag page where we can see the difference between both architecture styles (Slicing architecture vs. GraphQL architecture).
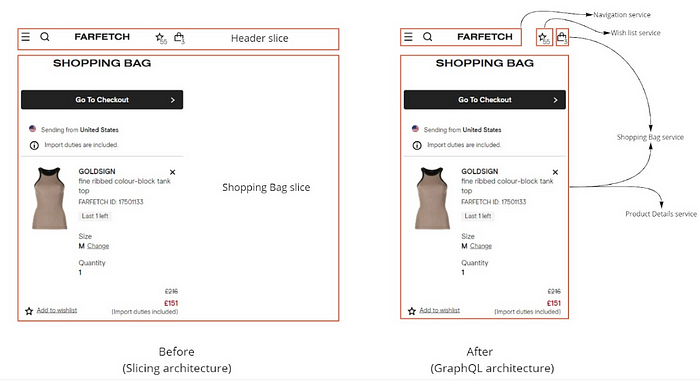
Previously, the header slice would have to fetch both the wishlist and shopping bag information to show up in the header section of the page (besides all the navigation information). Similarly, the shopping bag slice would have to fetch all the product details required to show all the products in the user’s bag.
Instead with a true “Back-End by Subject/Domain” approach, we would have to break this generalisation. Let’s try to understand how GraphQL could help here. The following is a very simple GraphQL query to extract some of the data to render the shopping bag along with the list of products and details.

This query would enable us to break up responsibilities and reuse the strengths of each downstream service in the Experience Layer. Bag-specific data would be resolved by the shopping bag service, while getting the details of each product in the user’s bag would be resolved by the product details service.
The product details service, formerly the product details slice, was only consumed in the context of the Product Details page main section. With this GraphQL architecture shift the product details service can now participate in any flow that requires detailed information about a specific product or products. The service no longer has a particular coupling where the data is going to be used or rendered. For this to happen, the schema needs to be built connecting all the pieces (GraphQL types) together in a big cohesive and consistent API.
Final Thoughts
By leveraging GraphQL, we can better scale our front-ends to meet the growing complexity of our services. For example, our recent launch of FARFETCH Beauty introduced new complexities to our ever-evolving product catalogue. We now have more ways to efficiently query product details, which might become a priority as your own data sources grow in complexity.
Our added service complexity also increased the specialisation, and complexity, of the development teams required to support great customer experiences across them all. Your own architecture evolution should scale to any growing specialisation of your front-end development teams.
This latest evolution of our Experience Layer also creates an opportunity to reduce the complexity of our back-ends and specialise them by domains, leveraging a true federated architecture.
In future articles, we will further expand on GraphQL and how we have been using it at Farfetch.com.